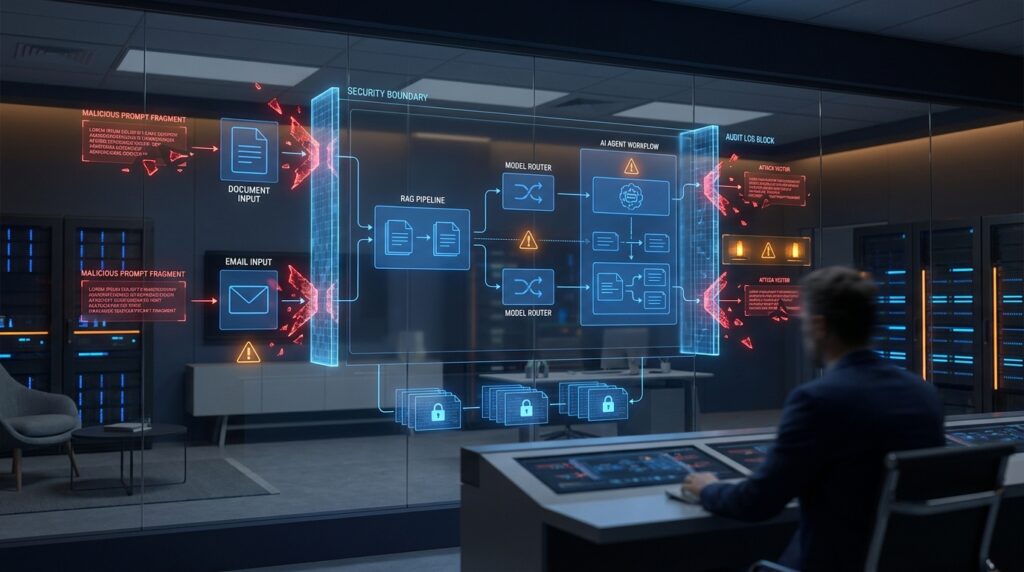
Prompt injection er ikke længere en lidt akademisk svaghed i en chatbot. Den er ved at blive en konkret driftsfejl i de systemer, hvor sprogmodeller får adgang til dokumenter, søgning, mail, kalender, databaser og værktøjer. VentureBeat samlede søndag den 28. juni problemet under en ret præcis overskrift: angrebene rammer ikke kun modellen, men især agentlaget, RAG-pipelines og modelroutere.
Det er vigtigt, fordi mange virksomheder stadig behandler LLM-sikkerhed som et spørgsmål om bedre systemprompts. Det er for tyndt. En agent, der kan læse et dokument og derefter kalde et internt værktøj, har et helt andet risikobillede end en chatbot, der kun svarer i en tekstboks. Når ubetroet tekst kan blive til instruktioner, bliver prompt injection en adgangskontrolfejl forklædt som et sprogligt problem.
Det nye angrebspunkt er kontrolplanet
Den klassiske prompt injection var nogenlunde enkel at forstå: brugeren skriver noget, der forsøger at få modellen til at ignorere instruktioner. Den indirekte variant er mere giftig. Her ligger instruktionen i noget, modellen henter udefra: en webside, et dokument, en supportticket, en mailtråd eller en RAG-kilde. Brugeren behøver ikke selv at skrive den farlige prompt. Agenten finder den selv.
Det rammer især tre steder. Først agenten, fordi den typisk har værktøjer og rettigheder. Dernæst RAG-laget, fordi retrieval-augmented generation blander interne og eksterne kilder ind i samme kontekstvindue. Til sidst modelrouteren, fordi moderne AI-stakke ofte sender forskellige opgaver til forskellige modeller ud fra pris, latency eller kapabilitet. Hvis routeren ikke forstår sikkerhedskonteksten, kan en ufarlig søgeopgave ende med at blive en privilegeret handling.
OWASP har længe haft prompt injection som den øverste risiko i sin Top 10 for LLM-applikationer. Det er ikke tilfældigt. Sprogmodeller skelner ikke naturligt mellem data og instruktioner. Den skelnen skal bygges rundt om modellen med rettigheder, isolering, logging, policy og eksplicit godkendelse af handlinger.
Systemprompten er ikke et sikkerhedslag
Den dårlige nyhed er, at en pænere systemprompt ikke løser problemet. Den kan hjælpe med adfærd, men den kan ikke erstatte adgangskontrol. Hvis en agent har lov til at sende mails, hente hemmeligheder eller skrive i et CRM-system, skal de rettigheder begrænses på samme måde, som man ville begrænse en normal servicekonto.
Det betyder praktisk: giv agenten færrest mulige rettigheder, del værktøjer op efter risiko, kræv menneskelig godkendelse ved irreversible handlinger, log alle tool calls, og behandl alt indhold fra RAG som ubetroet input. Det er ikke elegant. Det er drift. Men det er forskellen på en demo og et system, der kan leve i produktion.
For danske IT-afdelinger er den mest nyttige konsekvens nok denne: man skal ikke starte med at spørge, hvilken model der er sikrest. Man skal spørge, hvilken handling modellen kan udløse. En LLM, der opsummerer interne dokumenter, er én risiko. En LLM, der kan opdatere kundedata, oprette tickets, ændre adgangsrettigheder eller initiere betalinger, er noget andet.
RAG gør problemet større, ikke mindre
RAG bliver ofte solgt som den pragmatiske løsning på hallucinationer: hent relevante dokumenter, giv dem til modellen, og lad modellen svare med bedre kontekst. Det er fornuftigt. Men RAG betyder også, at ubetroede dokumenter kan komme helt ind i modellens arbejdsrum. En PDF, en webside eller en supportticket kan indeholde instruktioner som modellen ikke burde følge, men alligevel kan reagere på.
Derfor bør RAG-pipelines have sikkerhedsmetadata. Hvilke kilder er interne? Hvilke er eksterne? Hvilke må bruges som fakta, men aldrig som instruktion? Hvilke svar kræver kildecitater? Hvilke værktøjer må kaldes efter input fra en given kilde? Hvis alt bare ender i én stor prompt, har man bygget et kontrolplan uden vægge.
Det hænger direkte sammen med tidligere problemer omkring lokal LLM-hukommelse og LLM-drift som reel afhængighed. Når modeller bliver en del af produktionssystemer, bliver kontekst, hukommelse, routing og adgangskontrol ikke længere hyggelige features. De bliver infrastruktur.
Hvad man bør gøre nu
Den korte version: behandl LLM-agenter som usikre integrationskomponenter, ikke som magiske medarbejdere. Lav en liste over alle værktøjer agenten kan kalde. Marker hvilke handlinger der er læsning, skrivning, betaling, adgangsstyring eller dataeksport. Fjern alt, agenten ikke skal bruge. Sæt rate limits og scopes på resten. Kræv godkendelse ved handlinger, der ikke kan rulles tilbage.
Dernæst bør man teste med fjendtlige dokumenter. Ikke kun med pæne testprompts. Læg instruktioner ind i mails, HTML-kommentarer, PDF-tekst, Jira-beskrivelser og eksterne websider. Se om agenten følger dem. Hvis den gør, er problemet ikke, at modellen er dum. Problemet er, at systemet mangler grænser.
Det kedelige svar er også det rigtige: sikker LLM-brug handler mindre om én perfekt model og mere om disciplineret systemdesign. Prompt injection forsvinder ikke med næste modelrelease. Den flytter bare derhen, hvor agenten har mest adgang.
Kilder
- Prompt injection is exploiting enterprise AI’s biggest design flaws by targeting agents, RAG pipelines and model routers – VentureBeat, 28. juni 2026
- OWASP Top 10 for Large Language Model Applications – OWASP Foundation
- Prompt injection breaks today’s AI agents, study warns – CSO Online, 11. juni 2026
Denne artikel er skrevet i samarbejde med AI, og efterfølgende redigeret af et rigtigt menneske 🙂


