Language Models

Colibrì kan starte GLM-5.2 på en laptop med 25 GB RAM. Det er teknisk spændende, men stadig alt for langsomt til...

Programmatic tool calling i GPT-5.6 flytter agent-loopet ind i en V8-sandbox. Det kræver bedre API-kontrakter, audit og godkendelser.

Private LLM-endpoints gør åbne modeller mere realistiske i produktion. OCI viser, at modelvalg nu er infrastruktur, drift og governance.

GPT-5.6 lander i Microsoft 365 Copilot og ChatGPT Work. Det gør modelvalg, adgangsstyring og agenthandlinger til drift.
GPT-Live gør ChatGPT Voice til et live kontrolplan med modelrouting, sikkerhed og nye driftskrav for voice agents i produktion.

LLM-routing flytter modelvalg fra promptkode til kontrolplan. Pris, data, governance og geopolitik skal styres sammen.

Anthropic viser J-space i Claude: et muligt vindue ind i skjult LLM-ræsonnering, sikkerhedssignaler og agentkontrol.

Gemini Omni Flash flytter multimodal AI fra demo til drift. Det kræver budgetstyring, logging og klare regler for syntetisk medieproduktion.
GLM-5.2 viser, at open-weight LLM’er nu presser frontiermodeller på lange agentopgaver. Det sænker prisen, men øger kravene til kontrol.
Claude Sonnet 5 gør agentiske LLM-opgaver billigere og mere driftsnære, men sikkerhed, model-routing og tokenbudget er stadig dit ansvar.

GSA viser, hvor LLM-kontrakter er på vej hen: datakontrol, leverandørkæde, modelændringer og ansvar som driftskrav.
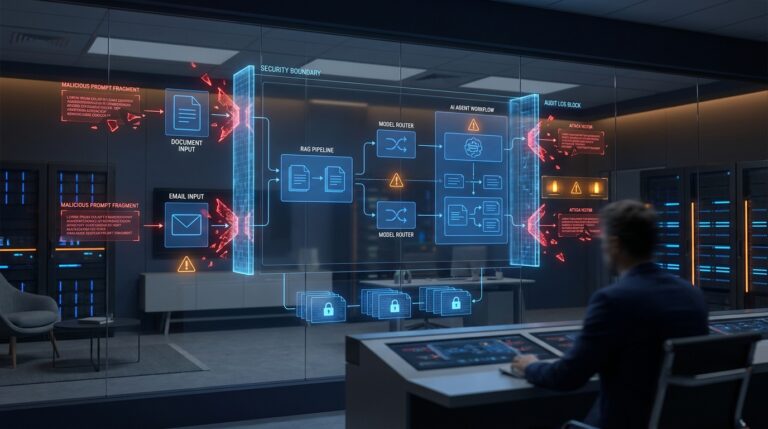
Prompt injection rammer nu LLM-agenter, RAG og modelroutere. Det er et kontrolplansproblem, ikke et promptproblem.

Claude Mythos 5 åbnes igen for udvalgte organisationer. Det gør LLM-adgang til et konkret driftspunkt for arkitekter og sikkerhedsfolk.

GPT 5.6 viser, at modeladgang nu er driftsrisiko: kunder, myndigheder og governance bliver en del af LLM-arkitekturen.

Claude Tag flytter LLM’er ind i Slack som delt agent med egen identitet, hukommelse og rettigheder. Det kræver drift, audit og...

PMB viser hvorfor lokal LLM-hukommelse kan blive kontrolplan for agentkodning: mindre glemsomhed, bedre audit og færre cloud-data.

Claude 529 fejl viser, at LLM-drift kræver fallback, logging og klare fejltilstande - ikke bare gode prompts og modelbenchmarks.

Claude Design kobler design systems og Claude Code. Det er mindre designhype og mere kontrolplan for agentisk softwareudvikling.

Rio-sagen viser hvorfor modelprovenans er blevet drift, compliance og indkøb - ikke bare AI-nørderi for open-weight-modeller.

LLM eksportkontrol rammer nu API-adgang direkte. Anthropic-sagen viser, at modelvalg er en driftsrisiko, ikke bare et benchmarkvalg.

SubQ er den første kommercielle LLM med subkvadratsisk sparse-attention arkitektur - 12M tokens, 81,8% SWE-Bench og en femtedel af frontiermodellernes pris.

Arcee AI har med kun 26 ansatte bygget Trinity Large Thinking, en 400B open source-sprogmodel under Apache 2.0 der scorer tæt...

Google lancerede Gemini 3.5 Flash den 19. maj 2026 - en frontier-model optimeret til agentiske workflows. Her er hvad benchmarks og...

Anthropic briefede det amerikanske Kongres om Claude Mythos' evne til at finde zero-day-sårbarheder. Modellen fandt 271 Firefox-bugs - og EU har...

Arcee AI har bygget Trinity, en open source sprogmodel med 400 milliarder parametre under Apache 2.0-licens. En lille startup med 26...

Claude modelpensionering den 15. juni viser, hvorfor LLM’er skal drives som versionerede produktionsafhængigheder.

Claude Covered Models gør 30 dages dataretention til en del af prisen for stærkere sprogmodeller. Det rammer enterprise-arkitektur.
DiffusionGemma viser, at lokale LLM workflows handler lige så meget om inferensarkitektur og latenstid som om modelkvalitet.
Agentbetalinger rykker fra demo til infrastruktur, når Visa og OpenAI kobler ChatGPT på betalinger med klare kontroller.

Claude Fable 5 viser næste lag i AI-infrastruktur: stærkere modeller, længere autonomi, dyrere inference og hårde sikkerhedsfiltre.